SQL Server CPU 성능 최적화
한눈에 보기:
- 데이터베이스 성능 문제 해결
- 하드웨어 원인 검토
- PerfMon을 사용하여 데이터베이스 병목 상태 추적
- 쿼리 성능 평가
데이터베이스 시스템의 성능 문제를 해결하는 작업은 매우 복잡할 수 있습니다. 문제가 어디에서 발생하는지 파악하는 것도 중요하지만 시스템이 특정 요청에 대해 현재와 같이 반응하는 이유를 알아내는 것이 더욱 중요합니다. SQL 문의 컴파일 및 재컴파일, 누락된 인덱스, 다중 스레드 작업, 디스크 병목 상태, 메모리 병목 상태, 일상적인 유지 관리 작업, ETL(추출, 변환, 로드) 작업을 비롯한 많은 요소가 데이터베이스 서버의 CPU 사용률에 영향을 줄 수 있습니다. CPU 사용률 자체가 나쁜 것은 아닙니다. 작업을 수행하는 것이야말로 CPU의 존재 이유니까요. 다시 말하지만 CPU 사용률을 적정 수준으로 유지하기 위해서는 CPU가 최적화되지 않은 코드나 느린 하드웨어에서 프로세서 주기를 낭비하는 대신 사용자가 원하는 작업을 처리하는 데 시간을 할애하도록 하는 것이 필수입니다.
서로 다르지만 목적은 같은 두 가지 방법
크게 봐서 CPU 성능 문제를 확인하는 방법은 두 가지입니다. 하나는 시스템 하드웨어의 성능을 검토하는 것입니다. 이 방법은 다음에 나오는 두 번째 방법에 따라 서버의 쿼리 효율성을 검토할 때 어느 부분을 조사해야 하는지 결정하는 데 도움이 됩니다. 일반적으로 두 번째 방법이 SQL Server™의 성능 문제를 파악하는 데 있어서 더 효과이지만, 쿼리 성능 문제의 원인이 어디에 있는지 정확히 알고 있는 경우가 아니면 시스템 성능부터 확인해 보는 것이 좋습니다. 대개는 두 가지 방법을 모두 사용하게 됩니다. 이제 이 두 가지 방법을 자세히 살펴보기 전에 기본적인 몇 가지 사항에 대해 알아보겠습니다.
기본 개념 형성
|
하이퍼 스레딩
하이퍼 스레딩은 SQL Server에 꽤 많은 영향을 주므로 이에 대해 자세히 설명할 필요가 있습니다. 하이퍼 스레딩은 각각의 물리적 프로세서에 대해 두 개의 논리적 프로세서를 OS에 제공합니다. 하이퍼 스레딩은 기본적으로 물리적 프로세서의 시간을 빌려 씀으로써 각 프로세서의 사용률을 높입니다. 하이퍼 스레딩의 작동 방법에 대한 자세한 설명은 Intel 웹 사이트( intel.com/technology/platform-technology/hyper-threading/index.htm )를 참조하십시오.
SQL Server 시스템의 경우 DBMS에서 고유의 매우 효율적인 큐 및 스레딩을 OS에 제공하므로 CPU 사용률이 이미 높은 시스템의 경우 하이퍼 스레딩은 시스템의 물리적 CPU를 오버로드하는 기능만 하게 됩니다. SQL Server가 여러 스케줄러에서 작업을 수행하기 위해 여러 개의 요청을 큐에 놓을 때 OS는 두 개의 논리적 프로세서가 동일한 물리적 프로세서에 있는 경우에도 계속해서 만들어지는 요청에 만족하도록 물리적 프로세서에서 스레드 컨텍스트를 실제로 전환해야 합니다. 물리적 프로세서당 Context Switches/sec가 5000 이상이면 시스템의 하이퍼 스레딩을 해제하고 성능을 다시 테스트해야 합니다.
드물기는 하지만 SQL Server에서 CPU 사용률이 높은 응용 프로그램이 하이퍼 스레딩을 효과적으로 사용할 수 있는 경우도 있습니다. 프로덕션 시스템에서 변경을 구현하려면 항상 먼저 하이퍼 스레딩을 각각 설정 및 해제한 상태로 SQL Server에서 응용 프로그램을 테스트해야 합니다. |
최고급 듀얼 코어 프로세서의 경우 시스템의 RAM보다 성능이 뛰어나므로 결국 연결된 저장 장치보다 속도가 빨라지게 됩니다. 성능이 우수한 CPU의 처리량은 현재 최고급 DDR2 메모리보다 6배 가량 많고 최고급 DDR3 메모리보다는 2배 가량 많습니다. 일반적인 메모리 처리량은 가장 빠른 파이버 채널 드라이브의 10배 이상입니다. 다시 말해 하드 디스크는 IOPS(초당 입/출력 작업 수)만큼의 한정된 작업만 수행할 수 있으며 이 수치는 드라이브 한 개가 수행할 수 있는 초당 검색 수에 따라 결정됩니다. 공정하게 비교하자면, 엔터프라이즈 데이터베이스 시스템의 모든 저장소 요구 사항을 처리하기 위해 단 한 개의 저장소 드라이브만 사용되는 경우는 드뭅니다. 현재 사용되는 대부분의 설치 프로그램은 엔터프라이즈 데이터베이스 서버의 SAN(저장 영역 네트워크) 또는 디스크 I/O 프로세서 문제를 없애거나 최소화할 수 있는 대규모 RAID 그룹을 사용합니다. 가장 중요한 점은 설치 프로그램의 형태에 관계없이 디스크 및 메모리 병목 상태는 프로세서의 성능에 영향을 줄 수 있다는 것입니다.
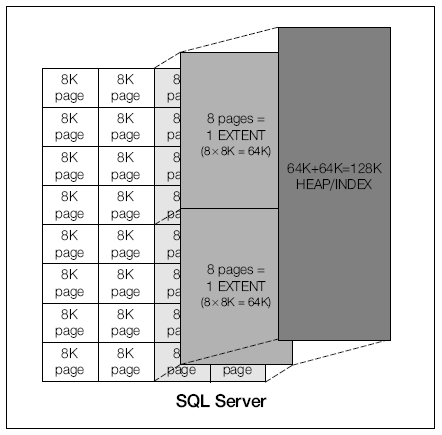
I/O 속도의 차이로 인해 디스크에서 데이터를 검색하는 경우 메모리에서 데이터를 검색할 때보다 비용이 훨씬 많이 듭니다. SQL Server의 데이터 페이지 하나는 8KB이고 익스텐트 하나는 8KB 페이지 8개로 구성되어 있으므로 64KB입니다. 이 값을 정확히 알고 있어야 하는데 그 이유는 SQL Server가 디스크에서 특정 데이터 페이지를 요청할 경우 해당 데이터 페이지뿐 아니라 데이터 페이지가 있는 전체 익스텐트가 검색되기 때문입니다. SQL Server의 경우 이렇게 비용이 많이 드는 데에는 이 외에도 많은 이유가 있지만 여기에서는 이에 대해 자세히 설명하지 않겠습니다. 이미 캐시된 데이터 페이지를 버퍼 풀에서 가져오는 데 걸리는 시간은 0.5밀리초 미만이고(성능이 최적인 경우), 디스크에서 단일 익스텐트를 검색하는 데 걸리는 시간은 2~4밀리초입니다(최적 환경의 경우). 일반적으로 성능 및 상태가 좋은 디스크 하위 시스템에서 읽는 경우 4~10밀리초가 걸릴 것으로 예상됩니다. 그리고 메모리에서 데이터 페이지를 검색하는 속도는 디스크에서 데이터 페이지를 가져오는 속도보다 4~20배가 빠릅니다.
SQL Server는 데이터 페이지를 요청할 때 디스크 하위 시스템의 데이터 페이지를 검색하기 전에 먼저 메모리 내 버퍼 캐시를 확인합니다. 데이터 페이지가 버퍼 풀에 있으면 프로세서가 데이터를 검색한 다음 필요한 작업을 수행하는데 이를 소프트 페이지 폴트라고 합니다. 소프트 페이지 폴트는 SQL Server에 가장 이상적입니다. 이는 요청의 일부로 검색되는 데이터를 사용할 수 있으려면 데이터가 먼저 버퍼 캐시에 있어야 하기 때문입니다. 버퍼 캐시에 없는 데이터 페이지는 서버의 디스크 하위 시스템에서 검색해야 합니다. OS가 디스크에서 데이터 페이지를 검색해야 하는 경우 이를 하드 페이지 폴트라고 합니다.
메모리 성능, 디스크 성능, CPU 성능을 연관 지어 검토할 때 처리량을 공통 분모로 정하면 전체적인 사항을 파악하는 데 도움이 됩니다. 그다지 과학적이지 않은 이 처리량이라는 용어는 유한한 파이프 안에 넣을 수 있는 데이터의 양에 대한 측정치입니다.
방법 1:시스템 성능
서버에 CPU 병목 상태가 있는지 확인하는 방법은 실제로는 몇 가지에 불과합니다. 또한 CPU 사용률을 높일 만한 원인도 그다지 많지 않습니다. 이러한 문제 중 몇 가지는 PerfMon이나 이와 비슷한 시스템 모니터링 도구를 사용하여 추적할 수 있고, 그 외 다른 문제는 SQL 프로파일러나 이와 비슷한 도구를 사용하여 추적할 수 있습니다. 쿼리 분석기나 SQL Server Management Studio(SSMS)를 통해 SQL 명령을 사용하는 방법도 있습니다.
시스템 성능을 평가할 때 필자는 광범위하게 시작해서 세부적으로 들어가는 방식을 취합니다. 분명한 건 문제가 있는 영역을 파악하기 전까지는 문제를 세부적으로 조사할 수 없다는 것입니다. 먼저 PerfMon 같은 도구를 사용하여 전반적인 CPU 사용률을 평가한 후 PerfMon에서 간단하고 이해하기 쉬운 몇 가지 성능 카운터를 살펴보는 것이 좋습니다.
가장 친숙한 성능 카운터 중 하나가 바로 % Processor Time입니다. 이 성능 카운터는 PerfMon에서 카운터 추가 창을 여는 경우 처음에 강조 표시되는 카운터입니다. % Processor Time은 프로세서가 작업을 실행하는 데 사용한 시간입니다. 최대 작동 시간 중 대부분의 시간 동안 이 값이 80% 이상일 경우 프로세서 사용률이 높은 것으로 간주됩니다. 서버가 사용률 80%에서 실행되고 있지 않을 때에도 수치가 100%에 이르는 때가 있는데 이는 일반적인 현상입니다.
PerfMon에서 System 성능 개체에 있는 Processor Queue Length 카운터도 검토해야 합니다. Processor Queue Length는 CPU에서 작업을 대기 중인 스레드 수를 보여 줍니다. SQL Server는 데이터베이스 엔진의 스케줄러를 통해 작업을 관리합니다. 즉, SQL Server는 데이터베이스 엔진을 통해 요청을 큐에 놓고 처리합니다. SQL Server는 작업을 자체적으로 관리하므로 각 논리적 프로세서에 대해 CPU 스레드를 하나만 사용합니다. 이는 SQL Server 전용 시스템의 경우 작업을 수행하기 위해 프로세서 큐에서 대기 중인 스레드 수가 최소한으로 유지되어야 함을 의미합니다. 일반적으로 SQL Server 전용 시스템에 있는 물리적 프로세서 수의 5배를 넘지 않아야 하지만 2배 이상만 되더라도 문제가 있는 것으로 생각할 수 있습니다. DBMS가 다른 응용 프로그램과 시스템을 공유하는 서버의 경우 이 카운터를 % Processor Time 및 Context Switches/sec 성능 카운터와 함께 검토하여 다른 응용 프로그램이나 DBMS를 다른 서버로 이동할 필요가 있는지 확인해야 합니다. 컨텍스트 전환에 대해서는 나중에 간단히 설명하겠습니다.
높은 CPU 사용률과 함께 프로세서가 큐에 대기 중인 것을 발견할 경우 필자는 SQL Server:SQL Statistics 성능 개체에 있는 Compilations/sec와 Re-Compilations/sec 카운터를 검토합니다( 그림 1 참조). 쿼리 계획 컴파일 및 재컴파일은 시스템의 CPU 사용률을 높입니다. Re-Compilations 값은 0에 가까워야 하지만, 시스템의 추세를 주의 깊게 검토하여 서버의 일반적인 동작과 정상적인 컴파일 수를 판단하는 것이 좋습니다. 재컴파일을 피할 수 없는 경우도 있습니다. 하지만 재컴파일 횟수를 최소화하고 쿼리 계획을 다시 사용하도록 쿼리 및 저장 프로시저를 최적화하는 것은 가능합니다. SQL Server:SQL Statistics 성능 개체에 있는 Batch Requests/sec를 검토하여 이들 값과 시스템으로 들어오는 실제 SQL 문의 수를 비교해 보십시오. 초당 컴파일 및 재컴파일 횟수가 시스템으로 들어오는 일괄 요청에서 높은 비율을 차지하는 경우 이 부분을 자세히 검토해야 합니다. SQL 개발자는 자신의 코드가 이러한 유형의 시스템 리소스 문제와 왜, 그리고 어떤 식으로 관련되는지 쉽게 파악할 수 없는 경우도 있습니다. 이 기사의 뒷부분에 나오는 참조 자료를 보면 이러한 유형의 작업을 최소화하는 데 도움이 될 것입니다.

그림 1 모니터링할 카운터 선택
PerfMon에서 Context Switches/sec라는 성능 카운터를 확인하십시오( 그림 2 참조). 이 카운터는 대기 중인 다른 스레드 대신 작업을 수행하기 위해 SQL 스케줄러가 아닌 OS 스케줄러에서 스레드가 전환된 횟수를 보여 줍니다. 컨텍스트 전환은 대개 IIS 또는 타 공급업체 응용 프로그램 서버 구성 요소와 같은 다른 응용 프로그램과 공유되는 데이터베이스 시스템에서 더 자주 발생합니다. 필자가 Context Switches/sec에 사용하는 임계값은 서버에 있는 프로세서 수의 5,000배 정도입니다. 하이퍼 스레딩이 설정되어 있으며 CPU 사용률이 적정 수준이거나 높은 시스템의 경우 이 값 또한 높을 수 있습니다. CPU 사용률과 컨텍트스 전환 횟수 모두 정기적으로 해당 임계값을 초과할 경우 CPU 병목 상태가 있음을 나타냅니다. 이러한 현상이 정기적으로 발생할 뿐 아니라 시스템이 노후되었다면 추가 CPU나 속도가 더 빠른 CPU 구입을 고려해야 합니다. 자세한 내용은 "하이퍼 스레딩" 추가 기사를 참조하십시오.
Figure 2 검토할 성능 카운터
| 성능 카운터 | 카운터 개체 | 임계값 | 설명 |
| % Processor Time | Processor | > 80% | 가능한 원인으로는 메모리 부족, 낮은 쿼리 계획 재사용, 최적화되지 않은 쿼리 등이 있습니다. |
| Context Switches/sec | System | > 5000 x 프로세서 수 | 가능한 원인으로는 서버의 다른 응용 프로그램, 동일한 서버에서 실행되는 둘 이상의 SQL Server 인스턴스, 하이퍼 스레딩 설정 등이 있습니다. |
| Processor Queue Length | System | > 5 x 프로세서 수 | 가능한 원인으로는 서버의 다른 응용 프로그램, 높은 컴파일 또는 재컴파일 횟수, 동일한 서버에서 실행되는 둘 이상의 SQL Server 인스턴스 등이 있습니다. |
| Compilations/sec | SQLServer:SQL Statistics |
추세에 따라 결정 | Batch Requests/sec와 비교합니다. |
| Re-Compilations/sec | SQLServer:SQL Statistics |
추세에 따라결정 | Batch Requests/sec와 비교합니다. |
| Batch Request/sec | SQLServer:SQL Statistics |
추세에 따라결정 | 초당 컴파일 및 재컴파일 횟수와 비교합니다. |
| Page Life Expectancy | SQLServer:Buffer Manager |
< 300 | 가능한 원인으로는 메모리 부족이 있습니다. |
| Lazy Writes/sec | SQLServer:Buffer Manager |
추세에 따라결정 | 가능한 원인으로는 대량 데이터 캐시 플러시 또는 메모리 부족이 있습니다. |
| Checkpoints/sec | SQLServer:Buffer Manager |
추세에 따라 결정 | PLE 및 Lazy Writes/sec를 기준으로 검사점을 검토합니다. |
| Cache Hit Ratio: SQL Plans | SQLServer:Plan Cache |
< 70% | 낮은 계획 재사용을 나타냅니다. |
| Buffer Cache Hit Ratio | SQLServer:Buffer Manager |
< 97% | 가능한 원인으로는 메모리 부족이 있습니다. |
CPU 사용률이 높을 경우 SQL Server 지연 기록기(SQL Server 2000) 또는 리소스 모니터(SQL Server 2005)라고 하는 영역도 모니터링해야 합니다. 버퍼 및 프로시저 캐시를 플러시하는 경우 리소스 모니터라고 하는 리소스 스레드를 통해 CPU 시간이 늘어날 수 있습니다. 리소스 모니터는 유지할 페이지와 버퍼 풀에서 디스크로 플러시해야 할 페이지를 결정하는 SQL Server 프로세스입니다. 버퍼 및 프로시저 캐시의 각 페이지에는 원래 해당 페이지가 캐시에 저장될 때 사용된 리소스를 나타내는 비용이 할당됩니다. 이 비용 값은 리소스 모니터가 값을 검사할 때마다 감소합니다. 요청에서 캐시 공간을 필요로 하는 경우 각 페이지와 관련된 비용을 기준으로 페이지가 메모리에서 플러시되며, 값이 가장 낮은 페이지가 가장 먼저 플러시됩니다. 리소스 모니터 작업은 PerfMon에서 SQL Server: Buffer Manager 개체에 있는 Lazy Writes/sec 성능 카운터를 통해 추적할 수 있습니다. 시스템의 일반적인 임계값을 확인하려면 이 값이 어떻게 변하는지 추적해야 합니다. 이 카운터는 메모리가 부족한지 여부를 확인하기 위해 일반적으로 Page Life Expectancy 및 Checkpoints/sec 카운터와 함께 검토합니다.
PLE(Page Life Expectancy) 카운터는 메모리가 부족한지 확인하는 데 유용합니다. PLE 카운터는 데이터 페이지가 버퍼 캐시에 머무르는 기간을 보여 줍니다. 이 카운터의 업계 허용 임계값은 300초입니다. 이 값이 일정 기간 동안 평균 300초 미만이면 데이터 페이지가 메모리에서 너무 자주 플러시되고 있다는 것을 나타냅니다. 이 경우 리소스 모니터의 작업량이 많아지고 이에 따라 프로세서가 감당해야 할 작업량도 늘어납니다. PLE 카운터는 Checkpoints Pages/sec 카운터와 함께 검토해야 합니다. 시스템에서 검사점이 발생하면 버퍼 캐시의 더티 데이터 페이지가 디스크로 플러시되고 이로 인해 PLE 값이 감소합니다. 리소스 모니터 프로세스는 실제로는 이러한 페이지를 디스크에 플러시하는 메커니즘입니다. 따라서 이러한 검사점 작업 중에는 Lazy Writes/sec 값이 증가하는 현상도 나타납니다. 검사점이 완료된 즉시 PLE 값이 증가하는 경우 일시적인 현상이므로 무시해도 됩니다. 하지만 PLE 값이 해당 임계값보다 낮은 현상이 정기적으로 발생할 경우에는 메모리를 추가하여 문제를 해결하는 동시에 CPU에서 사용할 수 있도록 일부 리소스를 해제하는 것이 좋습니다. 이들 카운터는 모두 SQL Server: Buffer Manager 성능 개체에 있습니다.
방법 2: 쿼리 성능
|
SP 추적 SQL Server 응용 프로그램을 추적하는 경우 추적에 사용되는 저장 프로시저에 친숙해지면 매우 유용합니다. 추적을 위해 GUI 인터페이스(SQL Server 프로파일러)를 사용할 경우 시스템 로드가 15~25% 정도 늘어날 수 있습니다. 추적에 저장 프로시저를 사용하면 이러한 시스템 로드를 절반으로 줄일 수 있습니다. 시스템의 특정 부분에서 병목 상태가 발생하고 있음을 알고 있고 서버에서 현재 이러한 문제를 일으키는 SQL 문이 어떤 것인지 확인하려는 경우 아래와 같은 쿼리를 실행해 보십시오. 이 쿼리를 실행하면 개별 문과 이러한 문이 현재 사용 중인 리소스는 물론 성능 향상을 위해 검토할 필요가 있는 문을 모두 함께 볼 수 있습니다. SQL Trace에 대한 자세한 내용은 msdn2.microsoft.com/ms191006.aspx 를 참조하십시오.
|
SQL Server로 새 쿼리가 제출될 때 쿼리 계획이 평가, 최적화 및 컴파일되어 프로시저 캐시에 저장됩니다. 서버로 쿼리가 제출될 때마다 요청과 일치하는 쿼리 계획이 있는지 확인하기 위해 프로시저 캐시가 검토됩니다. 일치하는 쿼리 계획이 없으면 SQL Server에서 새 쿼리 계획을 만들게 되는데 이 경우 비용이 들 수 있습니다.
다음은 T-SQL CPU 최적화를 위해 고려해야 할 몇 가지 사항입니다.
- 쿼리 계획 재사용
- 컴파일 및 재컴파일 횟수 줄이기
- 정렬 작업
- 잘못된 조인
- 누락된 인덱스
- 테이블/인덱스 검사
- SELECT 및 WHERE 절의 함수 사용
- 다중 스레드 작업
이제 이러한 사항에 대해 간단히 살펴보겠습니다. SQL Server는 일반적으로 메모리와 디스크 모두에서 데이터를 가져옵니다. 또한 사용자가 단일 데이터 페이지로만 작업하는 경우는 거의 없습니다. 오히려 관련 데이터를 전체적으로 볼 수 있도록 여러 개의 작은 쿼리를 실행하거나 테이블을 조인하는 등 한 레코드에 대해 응용 프로그램의 여러 부분이 작동하는 경우가 많습니다. OLAP 환경에서는 지역별 판매 보고서를 작성하기 위해 데이터를 통합, 취합 및 요약할 수 있도록 응용 프로그램이 한두 개의 테이블에서 수백만 개의 행을 가져올 수도 있습니다. 이 경우 데이터가 메모리에 있으면 데이터 반환 속도를 밀리초 단위로 측정할 수 있지만, 동일한 데이터를 RAM이 아닌 디스크에서 검색하는 경우에는 밀리초가 분으로 바뀔 수 있습니다.
첫 번째 예는 트랜잭션 양이 많은 경우로 응용 프로그램에 따라 계획 재사용 여부가 달라집니다. 이 경우 낮은 계획 재사용으로 인해 SQL 문의 컴파일 횟수가 대폭 늘어나 결국 CPU 처리량이 엄청나게 많아질 수 있습니다. 두 번째 예의 경우 대량의 새 데이터 페이지를 위한 공간을 만들기 위해 기존 데이터가 버퍼 캐시에서 지속적으로 플러시되어야 하므로 시스템 리소스 사용률이 높아지고 이로 인해 시스템 CPU의 처리량이 많아질 수 있습니다.
배송 상자 정보를 검색하기 위해 아래와 같은 SQL 문이 15분 동안 2000번 실행되는, 트랜잭션 양이 매우 많은 시스템이 있다고 가정해 보십시오. 쿼리 계획을 다시 사용하지 않을 경우 문당 개별 실행 시간이 450밀리초 정도일 것입니다. 쿼리를 처음 실행한 후 다음부터는 동일한 쿼리 계획을 사용한다면 이후의 쿼리는 실행되는 데 2밀리초 정도가 소요되어 총 실행 시간이 5초 정도로 줄어듭니다.
| USE SHIPPING_DIST01; SELECT Container_ID ,Carton_ID ,Product_ID ,ProductCount ,ModifiedDate FROM Container.Carton WHERE Carton_ID = 982350144; |
쿼리 계획 재사용은 트랜잭션 양이 많은 시스템에서 성능을 최적화하는 데 매우 중요한 요소이며 대부분의 경우 쿼리나 저장 프로시저를 매개 변수화함으로써 가능합니다. 다음은 쿼리 계획 재사용과 관련된 유용한 정보를 제공하는 리소스입니다.
- SQL Server 2005의 일괄 컴파일, 재컴파일 및 캐싱 계획 문제(microsoft.com/technet/prodtechnol/sql/2005/recomp.mspx)
- SQL Server 저장 프로시저를 최적화하여 재컴파일 방지(sql-server-performance.com/rd_optimizing_sp_recompiles.asp)
- SQL Server 2000의 쿼리 재컴파일(msdn2.microsoft.com/aa902682.aspx)
SQL Server 2005 DMV(동적 관리 뷰)도 많은 유용한 정보를 제공합니다. CPU 사용률이 높을 경우 CPU가 적절하게 사용되고 있는지 여부를 확인하는 데 사용할 수 있는 두 가지 DMV가 있습니다.
그 중 하나가 바로 데이터베이스 관리자가 SQL Server가 사용하는 각 리소스 유형 또는 함수를 확인하는 데 사용하는 sys.dm_os_wait_stats로, 이 DMV는 시스템이 해당 리소스로 인해 대기해야 하는 시간을 측정합니다. 이 DMV의 카운터는 누적됩니다. 따라서 미해결된 문제에 대한 데이터를 검토한 후에는 DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR) 명령을 실행하여 모든 카운터를 다시 설정해야 시스템의 여러 영역에 영향을 주는 리소스가 무엇인지 정확하게 검토할 수 있습니다. sys.dm_os_wait_stats DMV는 SQL Server 2000의 데이터베이스 일관성 검사를 위한 DBCC SQLPERF(WAITSTATS) 명령과 기능이 같습니다. 다른 대기 유형에 대한 자세한 내용은 SQL Server 온라인 설명서(msdn2.microsoft.com/ ms179984.aspx)를 참조하십시오.
모든 것이 최적으로 실행될 때조차도 시스템에서 대기 상태가 발생하는 것은 일반적입니다. 하지만 이러한 대기 상태가 CPU 병목 상태로 인해 발생하는지 여부는 확인해야 합니다. 신호 대기 시간은 전반적인 대기 시간에 비해 가능한 한 낮아야 합니다. 특정 리소스가 프로세서 리소스를 대기하는 시간은 총 대기 시간에서 신호 대기 시간을 빼면 알 수 있으며 이 값은 총 대기 시간의 약 20%를 넘으면 안 됩니다.
sys.dm_exec_sessions DMV는 SQL Server에서 열려 있는 모든 세션을 보여 줍니다. 이 DMV는 각 세션의 성능과 각 세션이 시작된 이후 세션에서 수행된 모든 작업을 자세히 보여 줍니다. 여기에는 세션이 대기한 총 대기 시간, 총 CPU 사용량, 메모리 사용량, 읽기 및 쓰기 수가 포함됩니다. 이 DMV는 로그인, 로그인 시간, 호스트 컴퓨터, 세션에서 마지막으로 SQL Server 요청이 이루어진 시간도 보여 줍니다. CPU 사용률이 높을 경우 가장 먼저 검토해야 할 항목 중 하나가 바로 sys.dm_exec_sessions인데 이는 이 DMV가 활성 세션에 대한 정보만 제공하기 때문입니다.
CPU 사용률이 높은 세션부터 먼저 검토하십시오. 작업을 수행 중이었던 응용 프로그램과 사용자를 확인한 후 자세한 분석을 시작하는 것이 좋습니다. sys.dm_exec_sessions와 sys.dm_exec_requests DMV를 함께 사용하면 sp_who 및 sp_who2 저장 프로시저를 통해 얻을 수 있는 정보의 대부분을 볼 수 있습니다. sql_handle 열을 통해 이 데이터를 sys.exec_sql_text DMF(동적 관리 함수)와 조인하면 세션에서 현재 실행 중인 쿼리를 확인할 수 있습니다. 그림 3 의 코드 조각은 이러한 데이터를 모두 가져와 서버의 현재 상황을 확인하는 방법을 보여 줍니다.
Figure 3 서버 작업 확인
| SELECT es.session_id ,es.program_name ,es.login_name ,es.nt_user_name ,es.login_time ,es.host_name ,es.cpu_time ,es.total_scheduled_time ,es.total_elapsed_time ,es.memory_usage ,es.logical_reads ,es.reads ,es.writes ,st.text FROM sys.dm_exec_sessions es LEFT JOIN sys.dm_exec_connections ec ON es.session_id = ec.session_id LEFT JOIN sys.dm_exec_requests er ON es.session_id = er.session_id OUTER APPLY sys.dm_exec_sql_text (er.sql_handle) st WHERE es.session_id > 50 -- < 50 system sessions ORDER BY es.cpu_time DESC |
이 문은 집중적으로 조사해야 할 응용 프로그램이 어떤 것인지 파악하는 데 도움이 됩니다. 필자의 경우 한 응용 프로그램 내의 모든 세션에 대한 CPU, 메모리, 읽기 수, 쓰기 수, 논리적 읽기 수를 비교한 결과 CPU 리소스가 다른 리소스보다 사용률이 훨씬 높다는 것을 알게 되었고 이때부터 해당 SQL 문을 집중적으로 분석하기 시작했습니다.
응용 프로그램에 대한 SQL 문을 과거부터 현재까지 시간별로 모두 추적하기 위해 필자는 SQL Server 추적을 사용했습니다. SQL Server 프로파일러 도구나 추적 시스템 저장 프로시저를 통해 SQL Server 추적에 액세스하면 시스템의 현 상황을 쉽게 평가할 수 있습니다. 이 항목에 대한 자세한 내용은 "SP 추적" 추가 기사를 참조하십시오. 프로파일러에서 CPU 사용률이 높고 해시 및 정렬 경고, 캐시 누락 및 기타 빨간색 플래그가 있는 문은 반드시 검토해야 합니다. 이런 식으로 특정 SQL 문이나 리소스 사용률이 높은 특정 시간대로 범위를 좁힐 수 있습니다. 프로파일러를 사용하면 SQL 문 텍스트, 실행 계획, CPU 사용량, 메모리 사용량, 논리적 읽기, 쓰기, 쿼리 계획 캐시, 재컴파일, 캐시에서의 쿼리 계획 제거, 캐시 누락, 테이블 및 인덱스 검사, 누락된 통계를 비롯한 다양한 이벤트를 추적할 수 있습니다.
필자의 경우 sp_trace 저장 프로시저나 SQL Server 프로파일러를 사용하여 데이터를 수집한 후에는 문제 발생 후의 추적 데이터로 채워지거나 데이터베이스에 쓰도록 추적을 설정하여 추적 데이터로 채워진 데이터베이스를 사용합니다. 문제 발생 후 데이터베이스를 채우는 작업은 SQL Server 시스템 함수 fn_trace_getinfo를 사용하여 수행할 수 있습니다. 이 방법을 사용할 경우 다양한 방법으로 데이터를 쿼리하고 정렬하여 CPU를 가장 많이 사용하거나 읽기 수가 가장 많은 SQL 문을 파악할 수 있을 뿐만 아니라 발생한 재컴파일 횟수를 계산하는 등의 많은 작업을 수행할 수 있습니다. 다음 예제에서는 이 함수를 사용하여 프로파일러 추적 파일이 있는 테이블을 로드하는 방법을 보여 줍니다. 기본적으로 해당 추적에 대한 모든 추적 파일이 생성된 순서대로 로드됩니다.
| SELECT * INTO trc_20070401 FROM fn_trace_gettable('S:\Mountpoints\TRC_20070401_1.trc', default); GO |
결론
지금까지 살펴보았듯이 CPU 사용률이 높다고 해서 반드시 CPU 병목 상태가 있는 것은 아닙니다. 높은 CPU 사용률에만 치중하다 보면 다른 응용 프로그램이나 하드웨어에서 발생하는 수많은 병목 상태를 놓칠 수 있습니다. 다른 카운터가 정상인데 CPU 사용률만 높을 경우 먼저 시스템 내에서 원인을 알아본 다음 CPU를 추가로 구입하거나 SQL 코드를 최적화하는 등의 해결 방법을 찾는 것이 좋습니다. 어떤 방법을 취하든 포기하지 마십시오. 약간의 실천과 탐구심을 갖고 이 기사에서 제시하는 방법을 적절히 활용한다면 'SQL Server에서의 CPU 사용률 최적화'라는 실행 계획을 실현할 수 있을 것입니다.
필자소개
Zach Nichter 는 10년 넘게 SQL Server 관련 분야에 종사해 온 SQL Server 전문가로, DBA, 팀장, 관리자 및 컨설턴트를 비롯한 다양한 SQL Server 지원 업무를 수행해 왔습니다. 현재 Levi Strauss & Co.에서 DBA 설계자로 근무하고 있는 Zach는 주로 SQL Server 성능, 모니터링, 아키텍처 및 기타 전략적 이니셔티브에 관한 업무를 담당하고 있으며 www.sqlcatch.com 에 게시된 동영상 블로그의 저자이기도 합니다.
'데이터베이스 > SQL Server' 카테고리의 다른 글
| 최근 Plan Cache Object 조회 (0) | 2009.08.27 |
|---|---|
| SQL Server 쿼리 성능 최적화 (0) | 2009.04.13 |
| 유용한 프로시저 (0) | 2008.11.07 |
| MSSQL 2005 - sp_send_dbmail 을 사용하기 위한 기본 설정 간단가이드 (0) | 2008.10.22 |
| SQL 파일 구조 - Pages and Extents (0) | 2008.09.29 |