32비트운영체제에서 MSSQL 2005은 메모리가 기본적으로 2기가만 지원을 하게 됩니다.
이것을 4기가까지 확장 할 수 있도록 하는 방법을 알려드립니다.
작업환경
OS : Windows Server 2003 Standard Edition 32Bit
SQL : MSSQL 2005 Server Standard Edition
RAM : 4GB
1. 컴퓨터의 실제 메모리는 아래 보시는것처럼 4기가의 메모리를 가지고 있습니다.
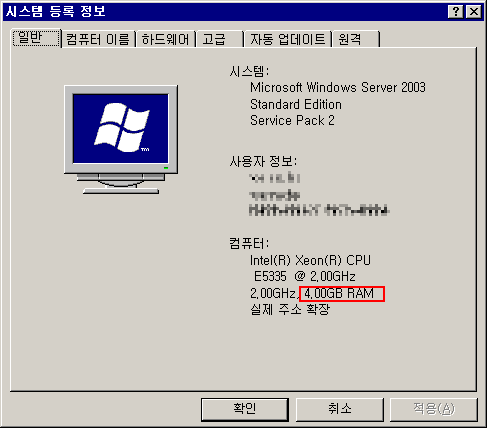
2. 하지만 MSSQL2005은 2기가까지만 메모리가 설정되어 있어서 그 이상은 사용을 하지 않는것을 볼 수 있습니다.
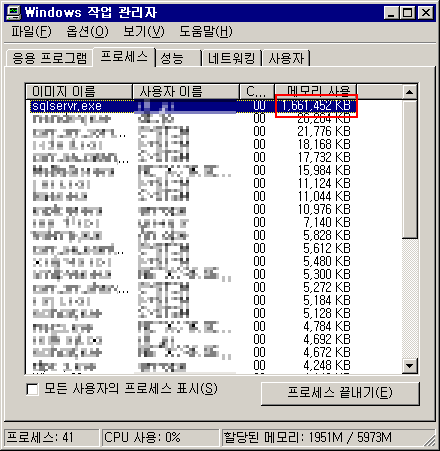
아깝지 않습니까? 이 풍부한 하드웨어에서 반밖에 능력을 사용 못하고 있네요.
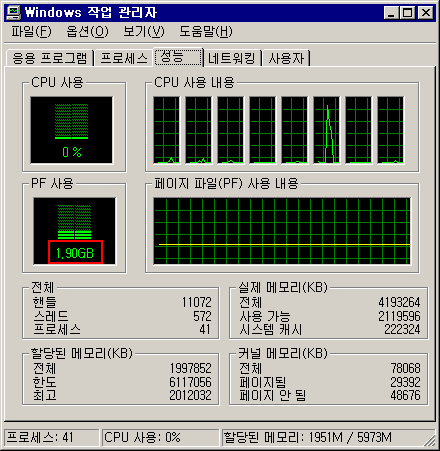
Lock Pages in Memory
3. MSSQL이 AWE를 사용하려면 Lock Rages in Memory 옵션이 지정된 윈도우 계정으로 MSSQL 엔진을 실행해야 합니다.
32비트 운영체제의 경우 SQL Server에 맞게 AWE를 구성하기 전에 Lock pages in memory권한을 얻어야 합니다.
4. 우선 MSSQL이 어떤 계정으로 구동이 되는지 알아야 합니다.
시작-> 프로그램 -> 관리 도구 -> 서비스 누른다음에 아래의 항목을 찾으면 됩니다.
'db_go' 혹은 'sql_starter'일것이다.
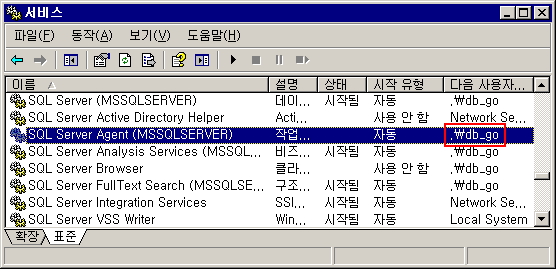
5. Lock Pages in Memory 옵션을 설정해야 합니다.
시작 -> 실행에서 gpedit.msc를 실행합니다.
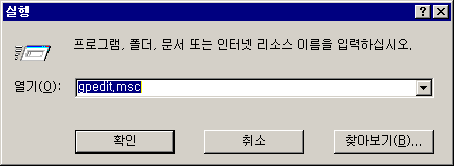
6. 그룹 정책 개체 편집기가 나오면..
컴퓨터 구성 -> Windows 설정 -> 보안설정 -> 로컬 정책 -> 사용자 권한 할당 -> 메모리의 페이지 잠그기
더블클릭을 합니다.
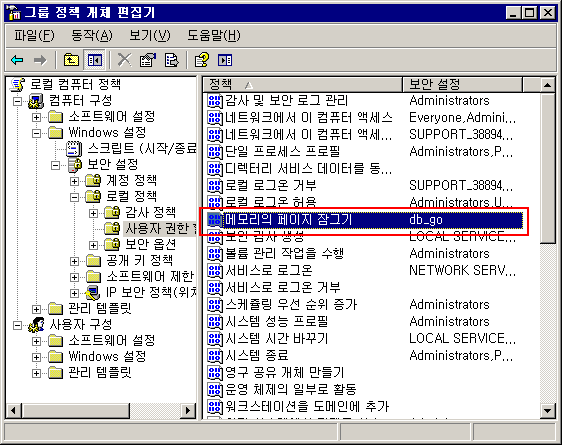
7. 아까 확인한 'db_go' 사용자를 추가를 해줍니다.
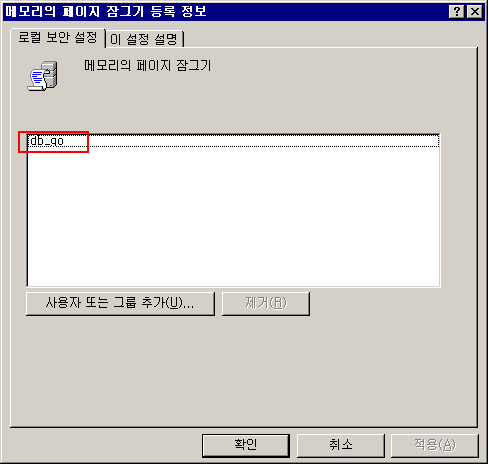
awe enabled 옵션
8. 본격적으로 메모리를 늘리는 방법을 진행하도록 하겠습니다.
AWE(Address WindowingExtionsions)를 사용하여 가상 메모리에 설정된 한계봐 더 큰 실제 메모리를 액세스 할 수 있도록 설정 하도록 하겠습니다.
'awe enabled'는 고급옵션입니다. 'sp_configure' 시스템 저장 프로시저를 사용하여 설정을 변경하려면 'show advanced options'를 1로 설정해야만 'awe enabled'를 변경할 수 있습니다.
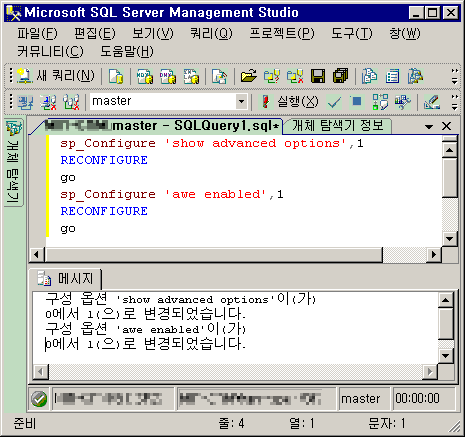
-------------------------------------------
sp_Configure 'show advanced options',1
RECONFIGURE
go
sp_Configure 'awe enabled',1
RECONFIGURE
go
-------------------------------------------
9. MSSQL을 다시 시작해야 합니다.
MSSQL을 다시 시작 한 후 메모리를 설정하겠습니다.
총 4기가중 3.5기가만 사용하도록 설정하겠습니다. 1024*3 = 3584
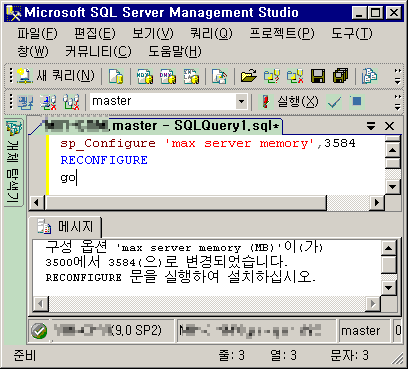
-------------------------------------------
sp_Configure 'max server memory',3584
RECONFIGURE
go
-------------------------------------------
네트워크 응용 프로그램을 위해 데이터 처리량 최대화
10. 네트워크연결에서 '파일 공유를 위해 데이터 처리량 최대화' 옵션을 선택하면 운영체제에서 파일 시스템 캐시에 I/O페이지를 캐시하여 버퍼링된 I/O작업을 수행하는 응용 프로그램에 우선 순위를 부여합니다. 이 옵션은 정상적인 작업을 수행하는 동안 SQL Server에서 사용가능한 메모리를 제한할 수 있습니다.
제어판 -> 네트워크 연결 -> 로컬 영역 연결 -> 일반 탭 -> Microsoft 네트워크용파일 및 프린터 공유 -> 속성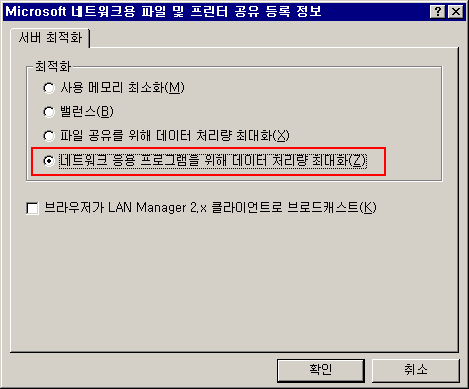
'네트워크 응용 프로그램을 취해 데이터 처리량 최대화'를 선택하고 확인을 누릅니다.
확인하기
여기까지 준비가 완료되었습니다.
메모리가 3.5기가까지 올라가나 확인하기 위해 무식한 쿼리를 날려보았습니다.
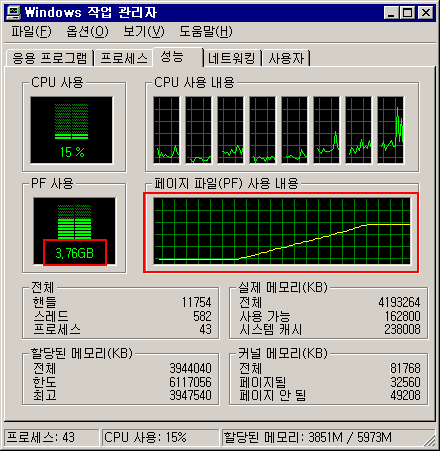
무하하...저 가파르게 올라가는 메모리양을 보십시오!!
성공했습니다.
[출처] MSSQL2005에서 2G이상 메모리 사용하기|작성자 쭈우
'데이터베이스 > SQL Server' 카테고리의 다른 글
| mssql txt or csv 파일 데이터 Insert (0) | 2008.04.28 |
|---|---|
| MSSQL CSV Bulk Insert (0) | 2008.04.28 |
| Oracle의 connect by 를 Mssql2005 의 CTE(WITH common_table_expression)로 변환 (0) | 2008.04.28 |
| MSSQL2005 사용자 계정추가 방법 (0) | 2008.04.28 |
| MSSQL2005에 등장한 각종 순위 함수 (0) | 2008.04.28 |
